CVL-CDSAML
Corpus-based Valency Lexicon for Contrastive and Diachronic
Study
Languages from Antiquity to Today
Open Access Research
All data and tools freely available
3,000 Years
From Homer to today
Computational Tools
Penn-Helsinki & PROIEL standards
Diachronic Analysis
Language evolution patterns
About CVL-CDSAML
CVL-CDSAML is an open access research project developing a comprehensive corpus-based valency lexicon for the contrastive and diachronic study of languages from antiquity to today. Funded by HFRI/ELIDEK, we employ Penn-Helsinki parsing standards and PROIEL treebank architecture to track valency patterns across 3,000 years of linguistic evolution.

Historical Corpus Development
Building annotated corpora from Homer to contemporary texts. Open access resources including diachronic retranslations.
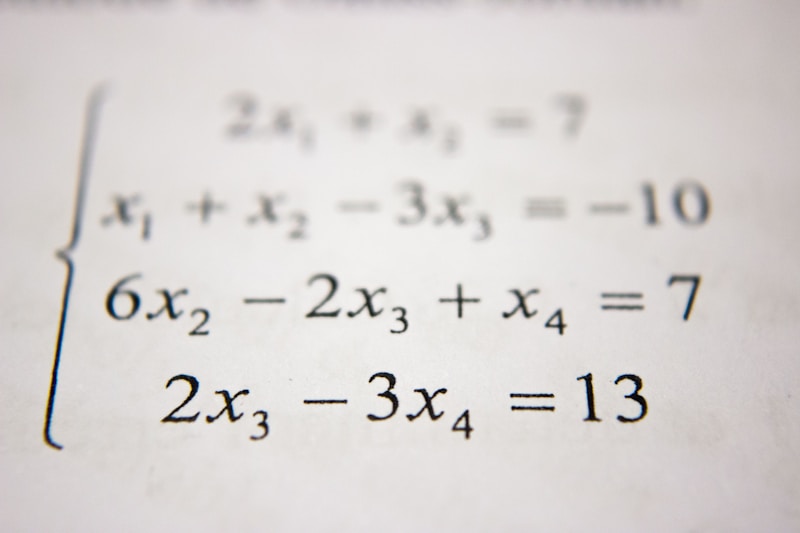
Computational Tools & Infrastructure
Utilizing Penn-Helsinki standards, PROIEL treebank architecture, and state-of-the-art NLP techniques. All tools and data are open access.

Valency Pattern Analysis
Systematic investigation of argument structure changes across language families, tracking evolutionary patterns over millennia.
Open Access Educational Videos
How Languages Evolve - TED-Ed
The Indo-European Connection
AthDGC Research Network
Integrated corpus resources, computational tools, and AI-enhanced platforms for diachronic linguistic research
CVL-CDSAML
Corpus-based Valency Lexicon
Main Project: Valency patterns across 3,000 years from Homer to today
Penn-Helsinki & PROIEL standards • Open access lexicon • HFRI/ELIDEK funded
Athens Diachronic Corpus
ΕΛΙΔΕΚ Project
10M+ tokens from Linear B to modern Greek
AI-powered analysis • Semantic change detection • Interactive visualization
Visit Site →AI Linguistic Platform
Automated Workflow System
AI-Enhanced Tools: Smart analysis, auto-parse, LightSide ML
Automated workflow • Claude AI integration • GitHub repository links
Visit Site →Parser & Processing Tools
Computational Infrastructure
Integrated Suite: Lavidas Parser, PROIEL processor, text analysis tools
Treebank integration • CoNLL-U format • Python & R packages
Indo-European Corpus
Comparative Analysis
Multi-language: Comparative diachronic analysis across IE languages
Ancient Greek • Latin • Sanskrit • Historical English • Germanic languages
Diachronic Valency Corpus
Specialized Collection
Focused Dataset: Verb valency patterns with detailed annotations
Version 2.0 • Enhanced annotations • Machine learning ready
🔐 All Research Resources Are Secure
Unified access with single sign-on • Protected research data • Collaborative team workspace
Research Objectives
Primary Research Questions
- Diachronic Evolution: How do valency patterns change from antiquity to today?
- Cross-linguistic Variation: What are the systematic differences in argument realization across language families?
- Language Contact: How do we distinguish between inherited valency patterns and those resulting from language contact?
- Diachronic Pathways: What are the typical trajectories of valency change across different language families?
- Computational Modeling: Can we predict valency changes using machine learning models trained on historical data?
- Cross-linguistic Patterns: Are there universal tendencies in how argument structures evolve over time?
Expected Outcomes
- Comprehensive digital corpus with 1+ million annotated tokens from antiquity to today
- Interactive online valency lexicon covering 5,000+ verbs
- Open-source computational tools for historical linguistics
- Diachronic retranslations database with open access
- Integration with Penn-Helsinki and PROIEL standards
- New theoretical insights into language change mechanisms
- Educational materials for university courses and summer schools
Research Team
Nikolaos Lavidas
National and Kapodistrian University of Athens
Specializing in historical syntax, language change, and corpus methodology.
Kiki Nikiforidou
Co-Investigator
National and Kapodistrian University of Athens
Professor of Linguistics specializing in construction grammar, lexicography, and language change.
Dag Haug
External Collaborator
University of Oslo
Creator of PROIEL treebank, specialist in computational historical linguistics.
Theodoros Michalareas
Post-Doctoral Researcher
National and Kapodistrian University of Athens
Specializing in corpus linguistics and computational approaches to historical analysis.
Vassiliki Geka
Post-Doctoral Researcher
National and Kapodistrian University of Athens
Focus on historical morpho-syntax and language variation in diachronic corpora.
Vassileios Symeonidis
Post-Doctoral Researcher
National and Kapodistrian University of Athens
Expert in digital humanities and computational text analysis.
Sofia Chionidi
PhD Researcher / Research Team Member
National and Kapodistrian University of Athens
Working on corpus annotation and linguistic data processing.
Anastasia Tsiropina
PhD Researcher / Research Team Member
National and Kapodistrian University of Athens
Focus on valency patterns and argument structure in historical texts.
Eleni Plakoutsi
PhD Researcher / Research Team Member
National and Kapodistrian University of Athens
Specializing in comparative historical linguistics and genealogical analysis.
PhD Dissertations in Progress
- Maria Episkopou: Diachronic retranslations and influential texts
- Georgia Stavrianopoulou: Diachronic retellings and influential narratives
Partners & Collaborators
University of Oslo
Department of Literature, Area Studies and European Languages
Partner institution for diachronic computational linguistics
PROIEL Treebank
Pragmatic Resources in Old Indo-European Languages
Open Access Infrastructure
Collaborative Tools & Standards
The project employs established computational linguistics infrastructure including Penn-Helsinki parsing standards, PROIEL treebank architecture, and open access tools for diachronic analysis. All resources, including diachronic retranslations and annotated corpora, will be freely available to the research community.
Research Timeline
Phase 1: Corpus Development
Phase I
Text collection and initial annotation of historical corpora from Homer to today.
Phase 2: Computational Tools
Phase II
Development of open access parsing tools and valency extraction algorithms.
Phase 3: Analysis & Lexicon
Phase III
Systematic analysis of valency patterns and construction of the interactive lexicon.
Phase 4: Open Access Release
Phase IV
Public release of all data, tools, and educational materials.
Educational Programs
Naxos Diachronic Linguistic School
Annual summer school on historical linguistics and corpus methods.
GlossaContact Lab
Research laboratory for language contact and diachronic retranslations.
CIVIS BIP: Diachronic Linguistics in the 21st Century
Intensive program on computational approaches to language change.
MA Program: English, Linguistics and Translation
Graduate program with specialization in historical and computational linguistics.
Open Access Video Resources
Educational videos about historical linguistics, language evolution, and computational methods
Introduction to Language Change
Computational Historical Linguistics
Corpus Methods Tutorial
Open Access Resources
Valency Lexicon
Interactive database of valency patterns from Homer to today
Corpus Query
Search annotated historical texts with Penn-Helsinki standards
Tutorials
Video guides and documentation for all tools
Downloads
Open access data, tools, and educational materials
Introduction to Our Open Access Tools
Publications
Publications from the CVL-CDSAML project will be listed here as they become available. All publications will be open access.
Contact
Principal Investigator
Prof. Nikolaos Lavidas
Division of Language-Linguistics
Department of English Language and Literature
School of Philosophy
National and Kapodistrian University of Athens
Email: nlavidas@enl.uoa.gr